ConcourseGPT - Taming the Beasts of CI/CD Infrastructure with AI-Generated Documentation
Solving the challenge of undocumented, complex Concourse pipelines with an AI-powered tool that generates comprehensive documentation for configurations that often remain untouched for months or years.
ConcourseGPT: Taming the Beasts of CI/CD Infrastructure
Concourse pipelines have become the backbone of many organizations’ delivery infrastructure, particularly wrt Cloud Foundry. These YAML configurations orchestrate everything from simple test-and-deploy workflows to complex multi-environment release strategies. But with great power comes a significant challenge: documentation debt.
Featured on Cloud Foundry Weekly Podcast
I recently had the opportunity to discuss ConcourseGPT on the Cloud Foundry Weekly podcast. Check out the full conversation below:
The Problem: Concourse Pipeline Sprawl
If you’ve worked with Concourse for any length of time, you’re likely familiar with this scenario:
- A pipeline starts simple, a few hundred lines of YAML, automates something amazing
- Over time, it grows to handle edge cases and new requirements
- Six months later, it’s a 3,000+ line behemoth that nobody fully understands
- The original author has moved to another team or company
- New team members are afraid to touch it: “It works, don’t break it!”
I personally experienced this pain while working with a platform team managing dozens of Concourse pipelines, some exceeding 5,000 lines of YAML. These configurations had evolved over years, with multiple authors and minimal documentation (none, actually). When something broke, the debugging process was painful and time-consuming - not because the fix was difficult, but because understanding the pipeline’s architecture and intent was the real challenge.
Enter ConcourseGPT: Documentation as Code
This frustration led me to create ConcourseGPT, an AI-powered documentation generator specifically designed for Concourse pipelines. The goal was simple: make it effortless to generate comprehensive, human-readable documentation that explains not just what a pipeline does, but why it does it that way.
ConcourseGPT analyzes your pipeline configuration files and produces detailed markdown documentation explaining:
- Pipeline architecture and purpose
- Individual jobs and their functions
- Resource configurations and interactions
- Pipeline groups and their relationships
The documentation is organized into a searchable static site using MkDocs with the Material theme, making it easy for teams to navigate and understand even the most complex pipelines.
How It Works
Unlike general-purpose documentation tools, ConcourseGPT understands Concourse-specific concepts and patterns. It’s built in Bash (for reasons I’ll explain shortly) and leverages large language models to analyze YAML configurations through a series of focused prompts.
The workflow is straightforward:
Analysis: The tool parses your pipeline YAML using
yqto extract structured information about jobs, resources, and groups.Chunking: For large pipelines (600+ lines), it intelligently breaks the configuration into manageable sections to ensure comprehensive analysis.
Documentation Generation: It creates markdown files for each component, including both explanatory text and the original YAML configuration for reference.
Site Building: Finally, it assembles everything into a searchable static site that can be hosted anywhere.
Why Bash?
Intentional choice. This decision might seem odd for a tool interfacing with AI APIs, but.. concourse users already live in a shell-heavy world. Pipeline authors regularly work with Bash scripts, shell-based tasks, and command-line tools. By building ConcourseGPT in Bash, I ensured that the tool would be immediately accessible to its target audience. There’s no new language to learn, no complex dependencies to install, etc.
The Impact: From Fear to Clarity
The difference good documentation gives engineers confidence when making changes. With ConcourseGPT, pipelines that were once intimidating black boxes become transparent, understandable systems:
- Onboarding: New team members can quickly understand pipeline architecture without reading thousands of lines of YAML
- Troubleshooting: When failures occur, engineers can confidently navigate to the relevant components
- Maintenance: Updates can be made with understanding of how components interact, reducing the risk of unintended consequences
- Knowledge Sharing: Teams build collective understanding instead of siloed expertise
One of the most powerful features is how ConcourseGPT handles large pipelines through chunking. Even for configs spanning thousands of lines, it produces coherent documentation that captures the overall architecture while still explaining individual components in detail.
Real-World Examples
Let’s look at a real example of what ConcourseGPT produces. Here’s a screenshot from documentation generated for a multi-environment deployment pipeline:
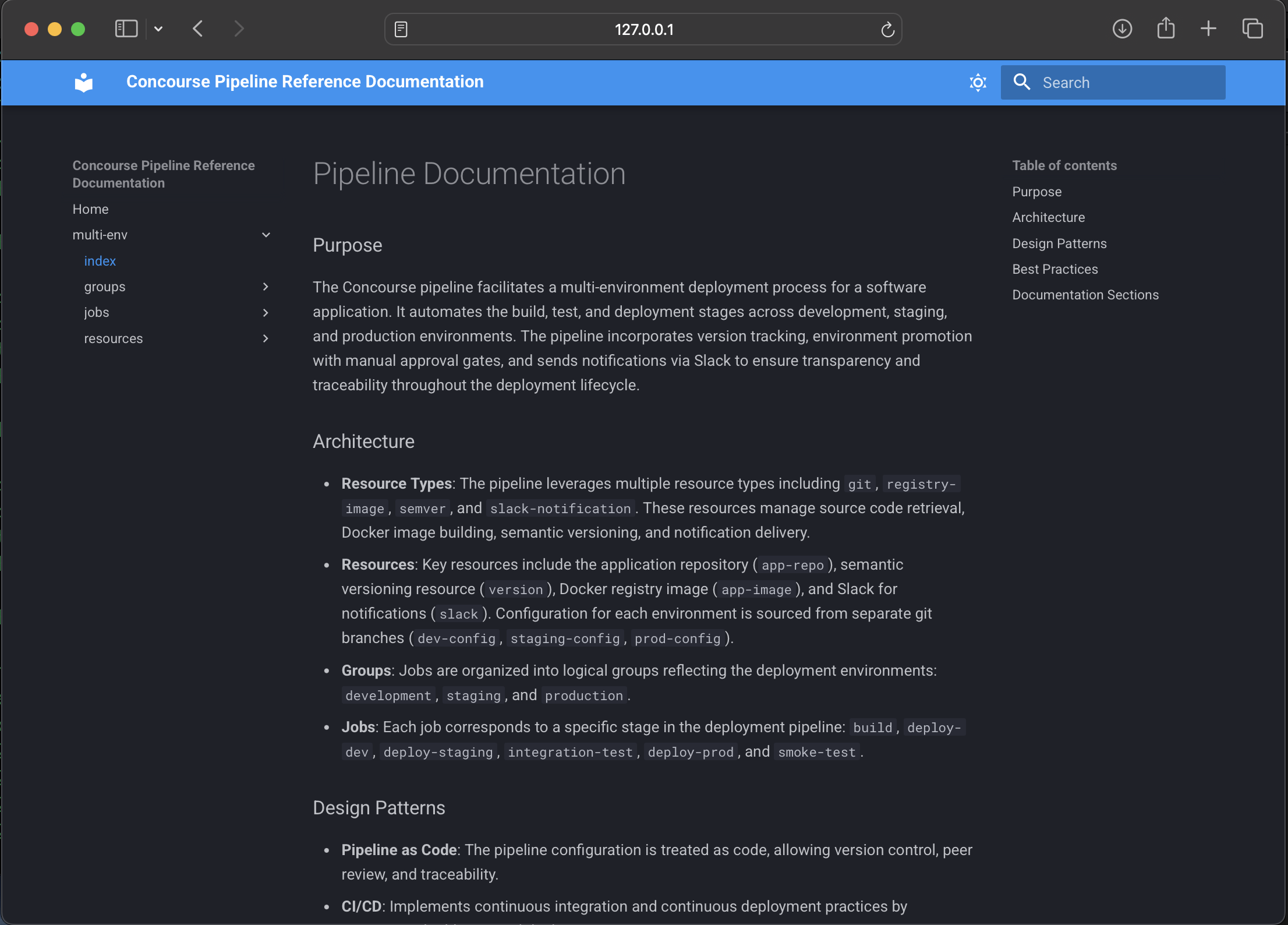
Compare this with trying to understand the same information by reading thousands of lines of YAML!
Getting Started
Using ConcourseGPT is simple:
1
2
3
4
5
6
7
8
9
10
11
12
# Set environment variables
export LLM_API_BASE="your-llm-api-endpoint"
export LLM_MODEL="your-model-name"
export VLLM_TOKEN="your-api-token"
# Generate documentation
concourse-gpt generate path/to/pipeline.yml
concourse-gpt gen-readme
# Build and serve the documentation site
concourse-gpt build-site
concourse-gpt serve
The tool is flexible enough to work with any LLM API that follows a standard chat completion format, including local models, giving teams options based on their requirements.
Conclusion: Documentation as a First-Class Citizen
ConcourseGPT represents a shift in how we think about CI/CD documentation. Rather than treating documentation as an afterthought, it makes comprehensive documentation a natural output of the development process.
For teams managing long-lived, complex pipelines that might go untouched for months or years, this approach is transformative. It acknowledges the reality that understanding existing infrastructure is often harder than building new infrastructure.
Infrastructure should be understandable, not mysterious. ConcourseGPT is one step toward making that ideal a reality.
Interested in contributing or trying ConcourseGPT? Check out the GitHub repository for more information and installation instructions.